На рассвете ИИ бума, который мы сейчас с вами переживаем, были такие люди, которые только то и делали, что промпты писали.
Сам помню это время, когда я рассказал проджект менеджеру, что он сам может писать промпты через генератор промптов от Anthropic, на меня тогда смотрели так, будто я открыл четвёртое измерение.
Так вот, Prompt Engineering постепенно эволюционировал в Context Engineering, который в свою очередь является неотъемлемой частью обязанностей ИИ инженера. Сейчас объясню что это такое и как это произошло.
Сначала языковые модели умели только отвечать на наши тривиальные и не совсем вопросы. Потом к этому добавился структурированный вывод (structured output), чтобы модель возвращала JSON’ы, которые мы с вами можем легко перекладывать. На базе этого появился вызов функций (function calling), который дал модели то, что сейчас называют «агентность» — взаимодействие с внешним кодом, запуск функций и принятие решений на основе их вывода. Потом у модели появилась возможность запускать собственно сгенерированный код в изолированном окружении (code interpreter tool). Следующий логичный шаг – MCP протокол, который позволяет ЛЛМ вызывать функции внешних микросервисов и стандартизирует коммуникацию между агентами и тулами. По сути, сейчас ЛЛМ является эдакой операционной системой, а MCP тулы — это драйверы (для браузера, для базы данных и т.д).
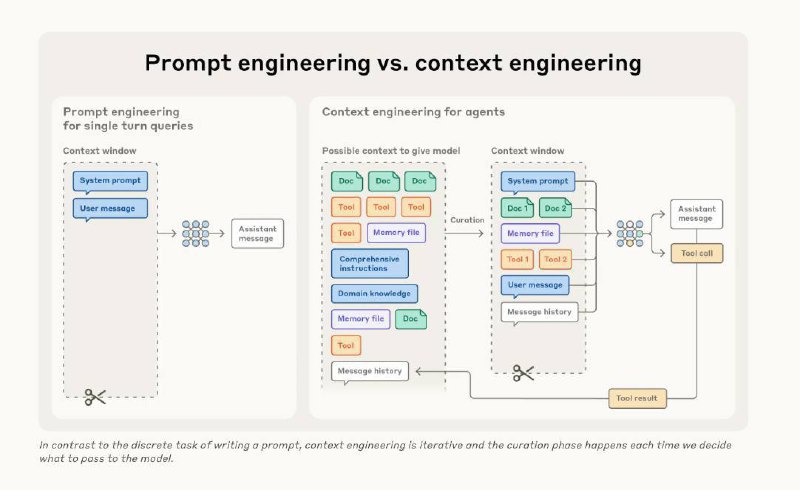
Prompt Engineering был релевантен, когда у модели не было такого количества разных вещей, которые нужно включать в контекст. Тогда было достаточно написать системную инструкцию и получить ответ от модели.
Сейчас, когда у модели есть tools, память (long term memory), чанки информации из RAG’а и инструкции, возникает необходимость правильно это сложить. «Чо тут сложного, всё запихнул в контекст и погнали», — скажете вы, но не так всё просто. Есть такое понятие как «гниение контекста» (context rot): это когда количество токенов в контекстном окне увеличивается, способность модели правильно строить связи между понятиями и источниками деградирует. Anthropic это называет «dilution effect» — чем больше нерелевантной информации в контексте, тем хуже модель справляется с задачей. В общем, на данный момент контекст должен восприниматься как что-то конечное, так как у ЛЛМ есть «бюджет внимания», и нам нельзя бросаться им во все стороны.
Главная цель context engineering’а – найти максимально компактный контекст, который максимизирует точность вывода модели. Теперь это не только написание инструкций, но и управление тем, какие данные попадают в контекст, когда и в каком объёме.
В следующей части расскажу практические советы о том, как организовывать контекст, где проходит баланс между слишком подробной и слишком расплывчатой инструкцией, и какие паттерны использую я в продакшн системах.
Stay tuned. @makebugger